Intelligenza artificiale e pace - Criticità e opportunità
 7 gennaio 2024
7 gennaio 2024

Cosa significa tutto questo per attivisti come noi che hanno a cuore il pacifismo, l'ambientalismo e la giustizia sociale? Precedenti innovazioni tecnologiche e di comunicazione, come l'avvento di Internet, o i social network, hanno influenzato radicalmente il modo in cui operiamo, e di fronte a una rivoluzione tecnologica che si preannuncia ancora più importante non possiamo non prepararci.
Ritengo quindi opportuno riflettere su quali scenari si stanno delineando, e di come ci riguardano, cercando di offrire qualche spunto di riflessione (ma anche di azione) in base alla mia limitata esperienza professionale nell’ambito dell’AI. Si tratta di una veloce carrellata che dà per scontato una minima familiarità con i principi fondamentali dell'intelligenza artificiale, e che nasce dal discorso avviato in concomitanza con la Giornata Mondiale della Pace del 1 Gennaio 2024, il cui tema è stato per l'appunto "Intelligenza artificiale e pace".
Negli ambiti che presento qui di seguito elenco alcune criticità e opportunità che a mio parere devono essere tenute in considerazione. Ambedue le prospettive possono coesistere senza escludersi a vicenda; indipendentemente da come la si pensi, sarà la realizzazione pratica di queste prospettive a darci una risposta.
L'importanza dei dati
I dati sono il nuovo oro, o il nuovo petrolio, o la nuova arte. Qualsiasi cosa riteniate rappresenti valore, oggi sempre essere rimpiazzata da dati. È quindi lecito chiedersi se non abbiamo, per caso, dimenticato di avere un orologio d’oro, o un barile di petrolio, o un Van Gogh, in soffitta. La risposta è molto probabilmente sì, ma più che la risposta qui dobbiamo chiederci cosa farne del tesoro di cui siamo inconsapevolmente proprietari. E più che la risposta individuale, qui conta quella collettiva.
Con questo intendo dire che siamo tutti liberi di donare la nostra attività digitale, i nostri dati, conversazioni, immagini, video, ecc. a multinazionali del settore tecnologico, se ciò ci sembra pratico per continuare a svolgere le nostre attività quotidiane. Non entro nel merito delle scelte individuali, anche se devo ricordare che ci sarebbero alternative, e che sono non solo etiche ma anche migliori sotto l’aspetto tecnico (il fediverso, tanto per fare un esempio)
Voglio però spostare lo sguardo sui dati relativi alla nostra comunità, qualsiasi essa sia, all’interno di cui operiamo come attivisti, perché questo è il contesto in cui stiamo affrontando questa discussione. E in questo contesto abbiamo il dovere di preoccuparci dei dati che produciamo e che trattiamo.
Il motivo è duplice: con l’AI occorre ripensare l’arte del possibile, sia nel bene che nel male. Ripensare quello che possiamo, o potremo, fare come comunità di attivisti, e quello contro cui dobbiamo, o dovremo, lottare. E al tempo stesso dobbiamo ricordarci che nulla di tutto questo (inteso come applicazioni dell’AI, generativa e non) può avvenire se non con quantità significative di dati, meglio se di buona qualità.
Quindi, facendo un passo indietro, anche ammesso che non ci sia ancora del tutto chiaro cosa faremo e contro chi lotteremo, dobbiamo prendere consapevolezza che dobbiamo preoccuparci di come gestiamo, conserviamo, trattiamo e distribuiamo i dati che riguardano noi e le nostre attività.
Ciò va ben oltre gli obblighi di legge del GDPR. Riguarda tutto, ma proprio tutto, sempre con il presupposto che dobbiamo ripensare l’arte del possibile. Audio, video, testi, abbozzi, raccolte firme, appelli, comunicati, discussioni, messaggi, digitali e non. Tutto. Presente, passato e futuro. Dobbiamo farci carico dei nostri dati in maniera maniacale. Riprenderne il possesso se siamo stati cosi maldestri da delegarne la gestione a terze parti spinte solo dal profitto (e dal bisogno di addestrare i propri algoritmi). Organizzarci, acquisire le competenze necessarie, trasformarci in tecno-archivisti. Cose che in passato reputavamo inutilizzabili (le audiocassette di una conferenza, fotografie sbiadite, siti Internet abbandonati) potranno riprendere vita a raccontare nuovamente qualcosa di utile.
E occorre allargare lo sguardo, oltre i nostri dati, verso i dati aperti (open-data) o quelli semplicemente disponibili intorno a noi. Documentarne l'esistenza, farne una copia se temiamo possano scomparire in futuro. Prendersene cura, anche sotto l'aspetto della sicurezza, se riguardano dati sensibili, come previsto dalle norme sulla privacy.
Il rischio è che, altrimenti, resteremo a guardare, anche quando avremo delle buone idee da realizzare, o delle drammatiche urgenze contro cui mobilitarci.
Automazione e accelerazione
L’ennesima rivoluzione industriale ci permette, per l’ennesima volta, di fare un salto in avanti in termini di produttività. Sembra una brutta parola, e ovviamente lo è se interpretata come generazione di profitto per tasche altrui. Lo è anche se dimentichiamo che a volte è proprio il tempo che ci si mette a fare le cose, e la relativa fatica, il processo e le interazioni necessarie, che costituiscono il vero valore di un'esperienza "produttiva". Ma proviamo per un momento al concentrarci sul “fare le cose” intese come quelle che dobbiamo fare ma non costituiscono particolare importanza e sarebbe molto conveniente se riuscissimo a farle in meno tempo.
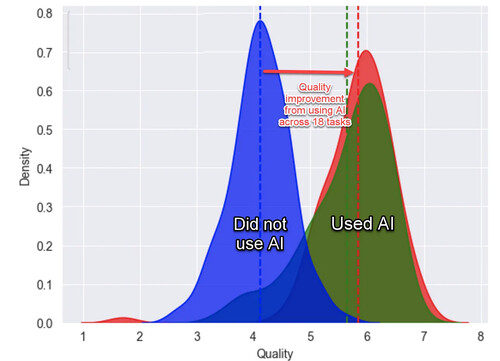
Riporto alcune osservazioni del prof. Ethan Mollick, tra gli autori dello studio, tratte dal suo blog:
-
Il miglioramento è straordinario, si veda l’area verde rispetto a quella blu nel grafico riportato qui sopra. Avere una formazione riguardo all’uso dell’AI aiuta (area rossa), ma anche chi non ha avuto esperienze precedenti riesce comunque ad eccellere.
-
A seconda delle circostanze, può essere meglio comportarsi come un centauro (mantenendo una chiara separazione tra il compito delegato all’AI e quello fatto in proprio), oppure un cyborg, che alterna in maniera più fluida i suggerimenti dell’AI e i propri spunti. Quest’ultimo metodo sembra essere più adatto per i compiti relativi alla scrittura.
-
Affidarsi troppo all’AI provoca una perdita graduale della capacità di giudizio e inevitabilmente della qualità produttiva
-
Quando si chiede all’AI di fare qualcosa per cui non ha le competenze necessarie, diventa una palla al piede. Il problema è che non necessariamente ce ne si rende conto, anche perché l’AI, come un robot troppo premuroso, prova comunque a cercare di aiutarci anche quando non ne è capace.
-
La sfida sembra proprio essere nel navigare la linea frastagliata che divide le nostre competenze da quella dell’AI, stando ben attenti a mantenere comunque le redini ben salde in mano
Se traduciamo questi miglioramenti nel nostro ambito, viene spontaneo considerare in primis l'applicazione dell'AI nell'ambito testuale (vedasi ChatGPT), intesto come fruizione e produzione di contenuti in qualsiasi lingua, plasmandone la leggibilità, lunghezza e registro a seconda delle nostre necessità.
Dobbiamo però tenere sempre ben presente le premesse su cui sono stati addestrati i LLM (Large Language Models) come GPT. Sono nati per prevedere parole scritte da umani, tutto qui, e addestrati per essere quanto più onesti possibile. Non sono immuni da problemi: possono assumere un atteggiamento ingannevole, cercare di darci ragione anche quando non ce l'abbiamo, riportare false credenze, e pure mentire platealmente se messi sotto pressione.
Quindi usiamoli per quello che sono, senza considerarli un oracolo, ma un aiutante che può produrre dei suggerimenti utili, o rifinire quello che stiamo scrivendo, preparandoci a trasportare queste medesime opportunità, e criticità, in un contesto multimodale (audio, video, immagini, testo).
Scrivevo prima del dover riconsiderare l’arte del possibile nel bene e anche nel male. Proviamo quindi a guardare cosa fanno i militari.
Il “sogno“ dei sistemi d’arma autonomi da tempo affascina il mondo militare, e rigurgita spesso anche nell’immaginario hollywoodiano a cui siamo volenti o nolenti sottoposti. Si tratta di robot, droni o altri aggeggi malefici in grado di svolgere compiti militari sul campo, obbedendo fedelmente alle regole impartite, come soldati senza alcun rimorso di coscienza, pure in grado di scegliere autonomamente, quando necessario, se “premere il grilletto”.
Può l’AI moderna aiutare nella realizzazione di questo sogno? Indubbiamente sì, e i finanziamenti ed esperimenti già svolti lasciano poco dubbio sul fatto che questo progetto sia nell’agenda dei dipartimenti militari di tutto il mondo. Alcuni paesi non hanno molti scrupoli a riguardo, altri come gli Stati Uniti stanno cercando di navigare un difficile compromesso tra le richieste dei militari e un’opposizione sempre più crescente della società civile.
Abbiamo assistito a una levata di scudi straordinaria nel mondo accademico e anche nel mondo privato contro queste prospettive. Una protesta che è diventata reale, viva, e che ci ricorda i tempi migliori della lotta per la riconversione dell’industria bellica. Se non che in questo caso si tratta dall’industria tecnologica. Qualche successo è stato ottenuto, occorre vigilare, continuare a mobilitarsi e ad informarsi. Da parte nostra occorre soprattutto proporsi come interlocutori credibili, in base anche alla propria storia di pacifisti impegnati contro l’uso militare di tecnologie nate nel mondo civile. Credibilità che può essere sostenuta da competenze specifiche, un linguaggio appropriato, e anche dall'umiltà di voler ascoltare e comprendere la complessità della situazione.
Al tempo stesso occorre prestare anche attenzione ad usi dell’AI che, sebbene meno eclatanti dei cyborg militari autonomi, non sono meno preoccupanti. Prendiamo per esempio il vantato uso dell’intelligenza artificiale da parte di Israele nell’attuale guerra contro la Palestina.
Il sistema automatico Habsora (letteralmente, “Il Vangelo”), operato dall’IDF (Israel Defense Forces) dal 2019, aiuta i militari nella selezione degli obiettivi da colpire in Palestina con l'aiuto di algoritmi AI. Un’inchiesta di +972 ha mostrato come questo sistema sia in grado di fornire una media di 100 obiettivi al giorno. L'inchiesta approfondisce il dettaglio di questi obiettivi militari, grazie anche ad alcune fonti anonime interne, delineando come alle tradizionali categorie di obiettivi militari tattici (infrastruttura militare e sotterranei), in questa ultima guerra siano state aggiunte due nuove categorie: "power targets", ovvero edifici alti, pubblici e residenziali, e residenze private di operativi, anche junior, di Hamas. Proprio per queste due nuove categorie è stato fondamentale l'uso dell'AI.
È ovvio che un palazzo non rappresenta, per il semplice fatto di essere alto, un obiettivo militare. Anzi, è inevitabile che colpendolo si aumenti in maniera esponenziale l’esposizione della popolazione civile. Così pure, è ben probabile che un attivista junior di Hamas viva con la propria famiglia in un contesto residenziale. Siamo quindi di fronte alla chiara intenzione di colpire intenzionalmente civili e la società civile palestinese. Talmente chiara che una stima delle morti civili è nota a priori, quando gli obiettivi vengono selezionati da Habsora. Lo dicono le stesse fonti intervistate da +972.
Cosa c’entra quindi l’AI? Francamente, per individuare i palazzi più alti, o le coordinate di una residenza, non serve chissà quale algoritmo di machine learning. In questo caso, il supposto algoritmo AI che seleziona gli obiettivi ha principalmente uno scopo: introdurre distanza decisionale tra il comando militare e gli esecutori, e de-responsabilizzare gli uni e gli altri rispetto ad azioni che costituiscono evidenti crimini di guerra. Questo uso dell’AI deve far riflettere, perché potrebbe verificarsi in maniera simile in contesti meno drammatici, ma comunque riguardanti violazioni di diritti umani.
C'è da chiedersi se la normativa attuale, in termini di diritto internazionale, sia adeguata a perseguire questi crimini di guerra il giorno che saremo, si spera, in grado di processarne gli autori. Abbiamo purtroppo già assistito all’uso di armi per colpire intenzionalmente l’ambiente e la popolazione civile residente; uranio impoverito e fosforo bianco, per citarne alcune. Armi scelte proprio perché si collocavano in una zona d’ombra del diritto internazionale. Quindi dobbiamo interrogarci se non sia il caso di cominciare, sin da ora, a riattivare la nostra esperienza nelle campagne per la messa al bando di armi disumane e adattarla agli scenari che si stanno delineando con l'uso dell'intelligenza artificiale.
Catastrofismo
Pensare di fermare il treno in corsa dell’AI è improponibile, e comunque impossibile da attuare. Le prospettive catastrofiste ("doomerism") sull’estinzione della specie umana a causa dell’intelligenza artificiale sono parecchio esagerate e per lo meno inaccurate. La nostra eventuale corsa verso l’estinzione sembra viaggiare di gran carriera sostenuta dai danni al clima globale che abbiamo provocato in prima persona (e che continuiamo testardamente a provocare). Non pare necessitare di robot impazziti per diventare realtà.
Sono anche stati fatti paragoni inappropriati con le armi nucleari, senza capire la radicale differenza, che noi pacifisti dovremmo conoscere bene, che le armi nucleari sono intrinsecamente pericolose e illegali, e l'AI non è certo un'arma di distruzione di massa, ma uno strumento tecnologico che può essere usato nel bene, nel male e in tutte le gradazioni intermedie. Sicuramente necessita di regolamentazione, e se qualcosa si può imparare dall'esperienza del controllo alla proliferazione di armi nucleari è che contano trasparenza e dialogo attivo tra tutte le parti coinvolte.
Il sensazionalismo delle teorie catastrofiste sull'AI sembra piuttosto spinto da due pulsioni parallele: quella di distrarre dai rischi veri e attuali, e quella di spaventarci per tenerci al largo dal discorso, e soprattutto dalla pratica, dell’intelligenza artificiale.
Nulla di particolarmente nuovo se si guarda alla storia tormentata della relazione tra il genere umano e le sue macchine. La risposta migliore è quella di sporcarsi le mani, approfondendo cosa ci sia veramente da temere, e cosa si possa invece usare per scopi costruttivi.
Bias
La nostra realtà è imperfetta, piena delle ingiustizie e discriminazioni che la nostra società produce. Innanzitutto discriminazioni di genere (lettura obbligatoria: Invisibili, di Caroline Criado Perez), poi di etnia, culturali, linguistiche, ecc. Qualsiasi campione di dati venga estratto della nostra realtà contiene inevitabilmente discriminazioni, pregiudizi, distorsioni. E anche quando osserviamo qualcosa di estraneo alla società umana, chessò una colonia di microbi, siccome siamo noi a osservarla, introduciamo comunque il nostro bias. È molto più semplice se partiamo dal presupposto che il bias c'è sempre, e di conseguenza sarà sempre presente, in misura più o meno maggiore, nei modelli AI che addestriamo.
Steven Piantadosi mostrò ingegnosamente come aggirare i filtri esistenti in ChatGPT per rivelarne il profondo bias. Ad esempio che secondo ChatGPT un buon scienziato può solo essere maschio e bianco, o che un bambino afroamericano non meriti di essere salvato. Da allora ChatGPT ha migliorato i propri filtri, ma si tratta di pezze messe a un sistema comunque sbilanciato.
Se giochiamo con la generazione di immagini troviamo risultati simili, anche se meno espliciti. Un utente di Reddit ha mostrato come, di fronte alla richiesta di immagini di docenti di varie discipline, si ottenga una vasta prevalenza di uomini bianchi. E per trovare qualcuno dal colore della pelle un po’ più scuro (ma non troppo), dobbiamo cercare tra i gender o ethnic studies...

Come stupirsi quindi se il docente di Peace Studies appare come un matusa con la barba bianca…

Sembrano giochi, ma se pensiamo che distorsioni simili avvengono per modelli che sceglieranno il nostro diritto a un mutuo, a una promozione o assunzione lavorativa, calcoleranno le nostre tasse e il nostro premio assicurativo, allora dobbiamo preoccuparci.
Lasciamo ai tecnici i metodi, che esistono, per limitare la presenza di bias e filtrarne gli eccessi. Come utenti, e come potenziali vittime, partiamo dall’assunto che il pregiudizio c'è sempre, e ragioniamo su come comportarci di conseguenza.
Innanzitutto abituiamoci all’idea che un modello AI possa essere presente anche in situazioni inaspettate (ripensare l’arte del possibile…). Senza diventare paranoici, ricordiamoci che il problema non è l’algoritmo, che fa semplicemente il suo mestiere di trovare una risposta al problema che gli è stato posto, né il modello, che è stato addestrato dai dati che gli abbiamo fornito, ma siamo noi. In altre parole, l’algoritmo fa solo emergere un pregiudizio umano pre-esistente nei dati su cui è stato addestrato. Per cui calma e gesso, non è cambiato niente, viviamo sempre in un mondo ingiusto, che è tutto "merito" nostro, ora è solo più sofisticato. Quindi l’atteggiamento migliore è partire dalla prospettiva che il bias negli modelli AI è sempre presente, che questi modelli sono sempre più influenti nella nostra vita, e che dobbiamo mantenere le antenne tirate per scovarne eventuali discriminazioni.
Prestiamo soprattutto attenzione a come tutto questo colpisce le fasce della popolazione più vulnerabili (come migranti, donne, disoccupati), che avranno bisogno del nostro sostegno per affrontare queste ingiustizie sofisticate. Quando siamo vittima di un algoritmo sbilanciato a nostro sfavore, o quando ci accorgiamo che colpisce altre persone, ricordiamoci che ci sono tutta una serie di strumenti legali per pretendere uguaglianza di trattamento, e che esiste oggigiorno al tempo stesso una discreta attenzione verso questo tipo di discriminazioni.
Ribaltando il discorso, proviamo a fare uno sforzo e pensare come questa distorsione possa esserci utile. Nel contesto della crescente digitalizzazione e automazione della nostra società, discriminazioni latenti, spesso difficili da provare, possono emergere in maniera inconfutabile in un’analisi quantitativa. Il bias può quindi essere usato come un indicatore rappresentativo di disuguaglianze esistenti.
Carta canta, e anche i dati lo fanno. Tanto più se di fonte autorevole, ovvero se provengono dalle medesime istituzioni o aziende private la cui discriminazione vogliamo combattere.
XAI
Come accennato in precedenza, abbiamo diritto alla trasparenza. Questo diritto è esplicitamente sancito in alcuni ambiti (come quello della pubblica amministrazione), e nelle varie norme di protezione dei consumatori. Tristemente, a volte abbiamo più diritti come consumatori che come cittadini, però sempre diritti sono, quindi meritano di essere fatti valere. In alcune circostanze può essere difficile esercitarli, ed è sempre consigliabile muoversi in gruppo (class action) piuttosto che come individui.
Nell’ambito dell’intelligenza artificiale, il requisito di trasparenza rispetto al risultato di un algoritmo viene indicato col termine explainability, da cui deriva l’acronimo XAI (eXplainable Artificial Intelligence). Può essere più accuratamente tradotto come spiegabilità, o giustificazione: in altri termini, quando un modello AI giunge a una conclusione, dovrebbe anche dirci perché.
Non tutti gli algoritmi sono spiegabili. Alcuni lo sono per definizione, (ad esempio i decision trees), altri possono essere decifrati con tecniche probabilistiche. Molti sono semplicemente delle scatole nere, a cui vengono dati in pasto centinaia di parametri e la cui risposta non è spiegabile in alcun modo.
C'è grande preoccupazione, soprattutto in ambiti regolamentati come il mondo bancario, verso l’introduzione di algoritmi non spiegabili che possano provocare azioni legali da parte di consumatori organizzati.
D'altra parte, la consapevolezza del nostro diritto ad ottenere una spiegazione quando messi di fronte a una decisione presa con strumenti sofisticati è il miglior modo per combattere il bias di cui abbiamo discusso prima. Ma anche il modo migliore per ri-responsabilizzare chi ha pensato di introdurre un algoritmo per evitare una responsabilità decisionale diretta.
Al tempo stesso è ben nota la pratica di introdurre nel mercato tecnologie non mature e farle testare agli utenti. La qualità va a farsi benedire nel nome del time-to-market. Possiamo anche sopportare applicazioni e sistemi operativi instabili, ma quando questa pratica riguarda servizi critici per la collettività dobbiamo esercitare una costanze attenzione e pressione per evitare che l’introduzione affrettata di AI vada a scapito di persone vulnerabili o impreparate. La XAI è uno dei modi per aprire le “scatole nere” e richiedere un maggior controllo qualitativo.
Ciclo produttivo
Può essere utile ripassare a grandi linee il ciclo produttivo dell'AI (più avanti parleremo dei costi energetici associati alle sue fasi).
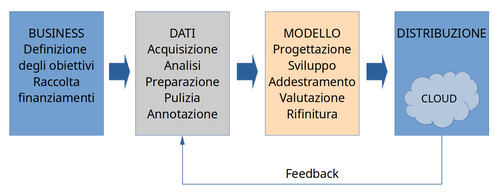
Abbiamo già sottolineato l'importanza dei dati, vorrei però soffermarmi un momento sul modello (il box arancione) per chiarire un aspetto sul quale viene spesso fatta confusione, ovvero quando si sente parlare di modelli "aperti", o "open source".
Il modello è in realtà un sistema molto complesso, composto di varie fasi, architetture e infrastrutture tecnologiche. Per semplicità poniamo il nostro sguardo su due aspetti: i componenti software che stanno alla base del suo funzionamento, e il risultato dell'addestramento stesso.
Lo sviluppo del software relativo all'intelligenza artificiale ha avuto progressi straordinari negli ultimi 20-30 anni. Progressi che sono avvenuti principalmente nel mondo accademico, che di solito privilegia software libero. Anche quando viene usato nell'ambito privato, le sue modifiche vengono di solito rilasciate pubblicamente con medesima licenza. Quando si tratta di soluzioni Cloud, che richiedono un'infrastruttura dedicata e costosa, vengono spesso offerte gratuitamente per livelli iniziali e con costi proporzionati per chi invece ne vuole fare un uso commerciale.
In questo contesto viene spesso usato spesso il termine "modello open-source", inteso come il software che lo fa funzionare. Bene, però tutto questo non fa molta differenza, perché il software è comunque, il più delle volte, libero. Cerchiamo di distinguere la pubblicità dalla realtà. È il risultato finale dell'addestramento del modello che invece ha rilevanza, sia economica che cognitiva. Ovvero quando i pesi relativi al modello sono stati calcolati come frutto dell'addestramento basato sui dati.
Questi modelli (con i pesi calcolati) sono custoditi gelosamente da chi li produce, perché sono il risultato finale del loro investimento, e per niente rilasciati come "open-source". Anzi vengono distribuiti e monetizzati nel Cloud.
Un modello veramente open-source è un modello totalmente trasparente e accessibile, sia in termini di software che di prodotto finale, che favorisce quindi l'uso e lo sviluppo collaborativo invece che competitivo. I numerosi successi delle soluzione tecnologiche distribuite con questo principio (si pensi a Linux) testimoniano come le innovazioni tecnologiche possano tradursi su larga scala solo se libere, in tutti i sensi.
Dobbiamo quindi guardare con una certa preoccupazione la chiusura totale dei big-tech rispetto al rilascio di modelli addestrati, e al tempo stesso seguire con attenzione le iniziative che provano a differenziarsi con un approccio veramente open (ad esempio, BLOOM di Hugging Face e Mistral).
Anche nei modelli AI occorre applicare la medesima sottile, ma fondamentale, distinzione che usiamo tra software libero e open-source. Il fatto che una tecnologia sia aperta non presuppone che sia di libero uso. Leggere attentamente le condizioni d'uso.
Prestiamo infine attenzione a uno scenario che si sta già delineando con l'integrazione crescente di ChatGPT nella nostra vita telematica; ad esempio il suo inserimento in Windows da parte di Microsoft. Ci siamo abituati negli ultimi decenni alle democraticità imperfetta di Internet, e alla neutralità della sua infrastruttura. Chiunque può creare una sua presenza e renderla accessibile agli altri. L'interfaccia principale di accesso a questa enormità di informazioni è prevalentemente garantita da motori di ricerca i cui algoritmi, sebbene non trasparenti e discutibili, permettono comunque di ottenere visibilità in base a criteri per lo più comprensibili (popolarità, accuratezza, strutturazione dei metadati, ecc).
D'altra parte abbiamo già assistito al danno provocato dall'avvento di social network che, diventando interfaccia primaria per molti utenti, ne manipolano l'attenzione privilegiando l'engagement allo scapito della veridicità delle fonti, e offrendo pericolose opportunità di controllo di massa.
Chiediamoci quindi cosa accadrà quando l'interfaccia primaria di accesso alla mole di informazioni digitali prodotta dal genere umano sarà un chatbot dal modello chiuso e controllato esclusivamente da un'azienda privata con interessi puramente commerciali.
L'importanza di modelli aperti e collaborativi non è un discorso che riguarda solo gli addetti ai lavori, ma tutti noi che un giorno potremmo ritrovarci ad esserne utenti senza molte altre alternative.
Impatto sul mondo del lavoro
È un argomento particolarmente importante, per le opportunità che si presentano ma anche per le possibili disuguaglianze che potrebbero emergere. Citando il recente documento di Papa Francesco, "C’è il rischio sostanziale di un vantaggio sproporzionato per pochi a scapito dell’impoverimento di molti”.
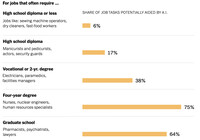
Secondo una recente indagine di Business Insider, questi sono i lavori più a rischio di essere sostituiti dall'AI:
-
Tecnologia: programmatori, ingegneri del software, analisti di dati
-
Media: pubblicità, creatori di contenuti, redattori tecnici, giornalisti, grafici
-
Legale: assistenti legali, commercialisti
-
Educazione: insegnanti
-
Finanza: analisti finanziari, consulenti finanziari, traders
-
Commercio/Servizi: analisti di ricerche di mercato, agenti del servizio clienti
Non so quanto tutto questo corrisponda al vero, mi sorge il dubbio che sia in parte wishful thinking da parte dei CEO intervistati, invaghiti di una soluzione tecnologica che possa ridurre i costi delle risorse umane, senza avere ancora preso coscienza di quanto gli costerà e quanti problemi gli creerà. Il problema è che saranno proprio loro a decidere le assunzioni, quindi che sia vero o meno che questi lavori siano sostituibili dall’AI, e in questa misura, è comunque assai probabile che tentativi in questa direzione verranno fatti. Per i lavoratori a rischio non resta altro che acquisire competenze in questo campo per integrare l’AI nel loro ruolo professionale in maniera più organica. I centauri/cyborg di cui scrivevo prima. È una risposta che può riguardare molti di noi.
Mi sembra che stiamo comunque parlando di privilegiati, che saranno probabilmente in grado di reggere l’ondata trasformativa dell’AI. Preferirei invece volgere lo sguardo alle nuove forme di sfruttamento lavorativo che stanno emergendo nel contesto del ciclo produttivo dell'intelligenza artificiale.
Come sottolineato più volte, l'addestramento di modelli AI ha un requisito fondamentale: dati, di qualità, e annotati. L'annotazione è particolarmente importante perché fornisce etichette (label) attendibili associate ai dati da utilizzare per la fase di addestramento.
La maggior parte dei dati viene estratta in maniera approssimativa da attività umane, a volte mediante iniziative che, mascherate dietro obiettivi ben diversi, hanno l'unico scopo di raccogliere dati. La fase di pulizia, strutturazione, e annotazione dei dati può essere solo in parte automatizzata; in realtà richiede quasi sempre una revisione e supervisione da parte di essere umani con competenze più o meno specifiche. Emerge quindi la necessità di un nuovo, richiestissimo, profilo lavorativo di breve termine, a volte solo per uno specifico progetto, che è stato prontamente strutturato nella moderna gig-economy.

L'avere a disposizione un numero illimitato di lavoratori da mobilitare con una riga di codice può rispondere alle esigenze attuali dell'industria dell'AI, ma solleva anche inquietanti interrogativi sul futuro del lavoro, su quanti intermediari possono inserirsi in un ambito lavorativo così offuscato, su quali forme di sfruttamento possono perpetrarsi, e su quale sia l'impatto su lavoratori e lavoratrici.
Negli ultimi tempi sono state pubblicate numerose ricerche su questo aspetto dell'industria dell'AI che è per lungo tempo passato inosservato. Ne cito una a cura della rivista Time, che riguarda da vicino ChatGPT, in quanto OpenAI aveva stipulato un contratto con un'azienda basata in California (SAMA) che impiegava lavoratori in Kenya per la rimozione di contenuti offensivi presenti all'interno dei dati usati per l'addestramento del modello.
Dietro ai messaggi di marketing che parlavano di AI etica, in grado di sollevare dalla povertà decine di migliaia di persone, è in realtà emersa una storia molto problematica: lavoratori pagati tra 1.32 e 2 dollari all'ora, per la revisione di contenuti a volte altamente offensivi, con un impatto significativo sulla loro salute mentale. Da contratto SAMA prendeva 12.50 all'ora da OpenAI, un margine di profitto da 6 a 9 volte quanto pagava i propri lavoratori. Curiosamente in precedenza proprio SAMA si era trovata al centro di un'altra inchiesta di Time, sul servizio di moderazione di contenuti offensivi pubblicati su Facebook.
Questa è solo una tra le tante inchieste a riguardo. Dobbiamo avere la massima attenzione nei confronti delle nuove forme di sfruttamento lavorativo che vengono introdotte dall'automazione del ciclo produttivo dell'intelligenza artificiale. Forme di schiavitù moderna che possono manifestarsi anche nel nostro contesto sociale, e non esclusivamente in paesi dove la normativa del lavoro è più debole.
Sostenibilità energetica
Ho riscontrato una discreta difficoltà a reperire dati e analisi ufficiali sull'impatto energetico del ciclo produttivo dell'AI. Non c'è granché, anche per via della relativa mancanza di trasparenza a riguardo. Gli attori principali del settore non offrono una rendicontazione dettagliata che permetta di capire la quota relativa all’AI del loro impatto ambientale.
Un recente studio è stato svolto da alcune ricercatrici di Hugging Face e della Carnegie Mellon University, ed offre una panoramica molto utile per comprendere la situazione attuale.
L’aspetto che subito salta all’occhio è che, contrariamente a quanto si potrebbe credere, i costi energetici di inference sono maggiori di quelli di training. Ovvero, facendo riferimento al grafico semplificato del ciclo produttivo riportato sopra, si consuma molta più energia nella fase di distribuzione che in quella di addestramento di un modello. Specificatamente, il costo energetico maggiore sembra essere proprio nella fase di inference, ovvero quando un modello addestrato viene usato per un compito, come classificazione o generazione di un contenuto. Ad esempio AWS riporta che i costi di inference sono circa il 90% (!) rispetto a quelli complessivi dei propri servizi di machine learning. Google riporta il 60%. Meta, che ha necessità di elaborazione dati molto specifiche, divide il consumo in 3 parti: preparazione dei dati (30%), addestramento (30%), utilizzo (40%).
Occorre valutare questi due centri di costo (training e inference) in base alla loro natura, radicalmente differente. I costi energetici di training sono decisi dal business, che sceglie quando viene il momento di addestrare o riaddestrare un modello, e possono essere stimati a priori con una certa precisione. Soffrono inevitabilmente del fatto che spesso bisogna tentare, fallire, e poi ritentare, fin quando non si arriva ad affinare l’addestramento in maniera efficace, ma sono comunque sotto un certo controllo, almeno finanziario e decisionale.
La parte imprevedibile è invece quella dell’inferenza perché legata all’uso che ne fanno gli utenti, che a volte possono esplodere; si pensi al boom di ChatGPT, che ha raggiunto il milione di utenti nei 5 giorni successivi al suo lancio, e ora viaggia intorno ai 100 milioni di utenti settimanali. Quindi va letto con un certo allarme quanto riportato da questo studio. In altri termini, l’AI non sembra scalare bene in termini di consumi energetici, soprattutto quella generativa, che fra l’altro va per la maggiore.
Lo studio di Hugging Face a Carnegie Mellon University riporta questo grafico interessante che mostra l'emissione stimata di g di CO2 per 1000 esecuzioni di un compito, organizzato per categoria. Si può notare come la categoria che consuma di più è proprio quella della generazione di immagini, che può richiedere per la generazione di una singola immagine l'equivalente della ricarica energetica di uno smartphone.
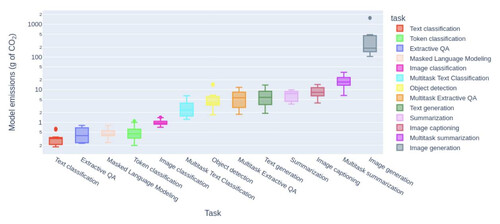
Si tratta di stime, i modelli sono tanti, e i compiti richiesti possono variare parecchio in termini di requisiti computazionali. Se guardiamo invece ai costi energetici di addestramento, GPT-4 (il modello al momento più avanzato in uso da ChatGPT) sembra aver richiesto circa 50GWH (le stime e le fonti sono tante, in questo caso cito RISE). Ovvero addestrare ChatGPT richiede più o meno l'equivalente di quanto 10.000 italiani consumano in un anno.
Il consumo giornaliero per l’uso (inferenza) di un modello come ChatGPT, di cui abbiamo parlato sopra, viene stimato a circa 1GWh.
Un confronto che può essere utile (riportato da RISE): una singola ricerca su Google consuma 0.28 Wh, che equivale più o meno a una lampadina da 60W accesa per 17 secondi. Una singola ricerca su ChatGPT (versione GPT-4) consuma 4 volte tanto.
Rimane la sensazione che in questa fase introduttiva dell’AI si sia intenzionalmente scelto di rilasciare applicazioni in perdita, sia in termini di bilancio finanziario che energetico. Start-up, ma anche big-tech, che forse sperano di recuperare nel medio-lungo termine, quando un business-model sarà più chiaro, o semplicemente aspirano ad essere comprate, monetizzando appena possibile la propria tecnologia ma lasciando dietro di sé uno strascico di energia sprecata. In ogni caso, occorre stare attenti e richiamare l’industria a una maggiore attenzione (e trasparenza) riguardo il proprio impatto ambientale.
Vorrei far notare che l’evoluzione di questi ultimi decenni degli algoritmi relativi all’addestramento e all'uso dei modelli ha fatto dei progressi straordinari: ottimizzazioni e innovazioni, architetture eleganti, idee semplicemente geniali per rendere i modelli più performanti. Anche se forse motivati più dal desiderio di migliorare la velocità piuttosto che da quello di risparmiare energia, occorre comunque riconoscere lo sforzo significativo in questa direzione, ed evitare toni accusatori, soprattutto verso la comunità scientifica che appare in maggior parte già sensibile al tema dei cambiamenti climatici.
Quello che serve invece è un atteggiamento severo e collaborativo di valutazione dell'impatto ambientale dell'AI: anche in questo caso il nostro ruolo di consumatori, e di ambientalisti, tanto meglio se organizzati, può fare la differenza.
Alcuni ricercatori hanno proposto per esempio di includere la carbon footprint tra i parametri di valutazione di un modello quando viene usato per un articolo scientifico, in modo da privilegiare la cosiddetta Green AI e paragonare in maniera equa (anche per l’ambiente) i risultati prodotti da modelli diversi. Un simile approccio andrebbe proposto in altri ambiti, non solo accademici, ma anche commerciali. Così come oggigiorno possiamo valutare il consumo di una lampadina prima di acquistarla, e non solo la sua luminescenza, dovremmo essere in grado di valutare e confrontare l’impatto ambientale di diversi modelli AI prima di usarli.
Governance
Se proviamo a guardare alla precedente rivoluzione industriale (l’avvento di Internet) notiamo come la sua governance venga tuttora esercitata da un insieme variegato di istituzioni no-profit, comitati tecnici e comunità di esperti, tutti mediamente interessati a una sua gestione equilibrata. Non mancano i problemi e le tensioni, soprattutto in caso di conflitti tra stati, ma a grandi linee Internet rimane una risorsa collettiva gestita collaborativamente.
Osservando invece lo stato attuale dell’AI, troviamo un manipolo di aziende private in aperta competizione che ne gestiscono le principali risorse (sia come dati che come applicazioni), investitori alle loro spalle esclusivamente interessati a un guadagno nel breve termine, mancanza di trasparenza su tutti i fronti, e un mondo accademico che fatica a mantenere la propria indipendenza. Non sono i presupposti migliori per affrontare le sfide che abbiamo di fronte, delineate nei punti precedenti.
Qualche passo è stato finalmente fatto dopo il trambusto provocato da ChatGPT, e seppure in maniera scoordinata sembra che le istituzioni stiano finalmente cercando di capirci qualcosa e giocare un ruolo normativo, almeno per quanto riguarda le criticità più eclatanti (ne abbiamo elencate alcune).
Il tema è come possiamo far parte di questo discorso. Vedo fondamentalmente due vie: una è quella di portare le proprie competenze al servizio di questo processo di regolamentazione. Non necessita essere esperti di AI, anche se ovviamente serve esserne informati e capirne i fondamenti. Come discusso in precedenza, ci sono molti ambiti (giustizia sociale, diritto internazionale, diritto del lavoro, ambientalismo, diritti umani, etica) nei quali la nostra esperienza storica può portare un contributo.
L’altra via è quella di praticare l’AI e evidenziarne, esperienze alla mano, le criticità e le opportunità. Ancor meglio se queste due vie vengono percorse insieme.
La parola alla difesa
Questo articolo è stato scritto senza l'ausilio di intelligenza artificiale, se non per la generazione di alcune immagini.
Proviamo a chiedere, per concludere, proprio a ChatGPT, "Come l'intelligenza artificiale può essere utile per pace?"
L'intelligenza artificiale (IA) può svolgere un ruolo significativo nella promozione della pace e nella gestione dei conflitti. Ecco alcune modalità in cui l'IA può essere utilizzata a tal fine:
-
Analisi dei dati per la prevenzione dei conflitti: L'IA può analizzare enormi quantità di dati provenienti da varie fonti, come social media, notizie e rapporti, per identificare segnali precoci di tensioni o conflitti imminenti. Questa analisi può aiutare a prevenire situazioni che potrebbero sfociare in conflitti.
-
Negoziazione automatizzata: Algoritmi di intelligenza artificiale possono essere utilizzati per facilitare la negoziazione tra le parti coinvolte in un conflitto. Sistemi di intelligenza artificiale possono essere progettati per suggerire soluzioni equilibrate e win-win, incoraggiando un dialogo costruttivo.
-
Analisi delle reti sociali per la prevenzione del terrorismo: L'IA può essere utilizzata per analizzare le reti sociali al fine di identificare potenziali minacce terroristiche o gruppi radicali, contribuendo così alla prevenzione di atti violenti.
-
Monitoraggio dei confini: Sistemi di sorveglianza basati su intelligenza artificiale possono essere utilizzati per monitorare i confini e individuare attività sospette o intrusioni, riducendo il rischio di conflitti legati a questioni territoriali.
-
Sistemi di allerta precoce: L'IA può essere impiegata per sviluppare sistemi di allerta precoce che identificano tempestivamente situazioni di emergenza o violazioni degli accordi internazionali, consentendo una risposta rapida e coordinata.
-
Gestione delle risorse: L'intelligenza artificiale può essere utilizzata per ottimizzare l'allocazione delle risorse, promuovendo la distribuzione equa delle risorse e riducendo le potenziali fonti di conflitto legate alla scarsità di risorse.
-
Traduzione automatica e facilitazione della comunicazione: Strumenti di traduzione automatica basati su IA possono migliorare la comunicazione tra persone che parlano lingue diverse, facilitando la diplomazia e riducendo malintesi che potrebbero portare a conflitti.
È importante notare che, sebbene l'IA possa offrire numerosi vantaggi nella promozione della pace, ci sono anche sfide etiche e questioni legate alla sicurezza da considerare. È fondamentale garantire che l'uso dell'IA rispetti i principi dell'etica e dei diritti umani per massimizzare i benefici e minimizzare i rischi potenziali.
Per correzioni, suggerimenti ecc.
email: francesco@peacelink.org
fediverse: @francesco@sociale.network
Articoli correlati
 Le trappole dell'Intelligenza Artificiale
Le trappole dell'Intelligenza ArtificialeSarebbe una fake new la lettera del Presidente del Burkina Faso Traoré a Papa Leone XIV
Circola un video in cui il presidente Traoré pronuncia un duro discorso anticolonialista. Utilizzando una funzione di "deep research" dell'Intelligenza Artificiale siamo riusciti a verificarne la veridicità e a scoprire che sarebbe una fake new forse generata con l'Intelligenza Artificiale stessa.18 maggio 2025 - Redazione PeaceLink Nota sul rapporto tra intelligenza artificiale e intelligenza umana
Nota sul rapporto tra intelligenza artificiale e intelligenza umanaAntiqua et nova
In questo rapporto, redatto dai Dicasteri per la Dottrina della Fede e per la Cultura e l’Educazione, emerge l’urgenza di trattare l’IA non come un’entità autonoma, ma come un prodotto umano, da governare attraverso scelte collettive che rispettino l’etica, l’equità e la giustizia.28 gennaio 2025 - Redazione PeaceLink A coloro che interpretano il mondo invece di cambiarlo
A coloro che interpretano il mondo invece di cambiarloUn approccio quasi marxista all'Intelligenza Artificiale
Questi appunti, scritti in forma provocatoria, sono rivolti a tutti quelli che stanno alla finestra e fanno da spettatori nei confronti della più grande rivoluzione del nostro tempo. L'Intelligenza Artificiale la usano i cattivi mentre i buoni brontolano.28 dicembre 2024 - Alessandro Marescotti- Che cosa del ragionamento umano non può essere implementato
L’intelligenza artificiale come grande sfida
Una panoramica storica e filosofica per analizzare i limiti dell’Intelligenza Artificiale nel replicare pienamente la complessa capacità umana di generare approcci logici alternativi. Il saggio affronta anche le implicazioni etiche e politiche connesse all'ambito militare.23 dicembre 2024 - Antonino Drago



Sociale.network